Executive Summary: The emergence of Large Language Models (LLMs) has revolutionized text classification, transitioning from traditional rule-based systems to advanced deep learning techniques. This evolution enhances applications like spam detection and sentiment analysis, offering more accurate and efficient solutions.
This article:
- Discusses the evolution of text classification with the advent of Large Language Models (LLMs).
- Explores applications in spam detection, sentiment analysis, and topic categorization.
- Highlights the shift from rule-based systems to deep learning and transformer architectures.
Introduction
As natural language processing (NLP) advances, text classification remains a foundational task with applications in spam detection, sentiment analysis, topic categorization, and more. Traditionally, this task depended on rule-based systems and classical machine learning algorithms. However, the emergence of deep learning, transformer architectures, and Large Language Models (LLMs) has transformed text classification, allowing for more accurate, nuanced, and context-aware solutions.
At Red Sift, our commitment to technology and innovation drives us to continuously explore and adopt cutting-edge methodologies, integrating them into our work to tackle complex challenges. In this article, we will explore some of the most advanced approaches to text classification and benchmark them against a traditional ML model, showcasing the power of innovation and highlighting the strengths and limitations of each.
Task and data
The classification task involves categorizing website content into one of 15 industry sectors, aligned with NAICS codes.
The test set comprises 1,500 websites, with 100 samples per class. To evaluate how each technique performs with varying amounts of training data, we adjust the training set size across five levels: 100x, 200x, 400x, 800x, and 1600x. Here, “100x” corresponds to 100 data points per class (totaling 1,500 data points), allowing us to observe each method’s effectiveness as the dataset scales.
Techniques and results
Baseline: Bag of words
Before applying any ML models, text data needs to be transformed into numerical vectors. One of the most basic and popular techniques for text vectorization is the Bag of Words (BoW). It creates a vocabulary of all unique words in the corpus and represents each document as a vector where each element corresponds to the presence of a word in the vocabulary. Alternatively, we can use the frequency of the word in the document or a more sophisticated TF-IDF score (a formula that takes into account the frequency of the word in the document and the frequency of the word in the corpus).
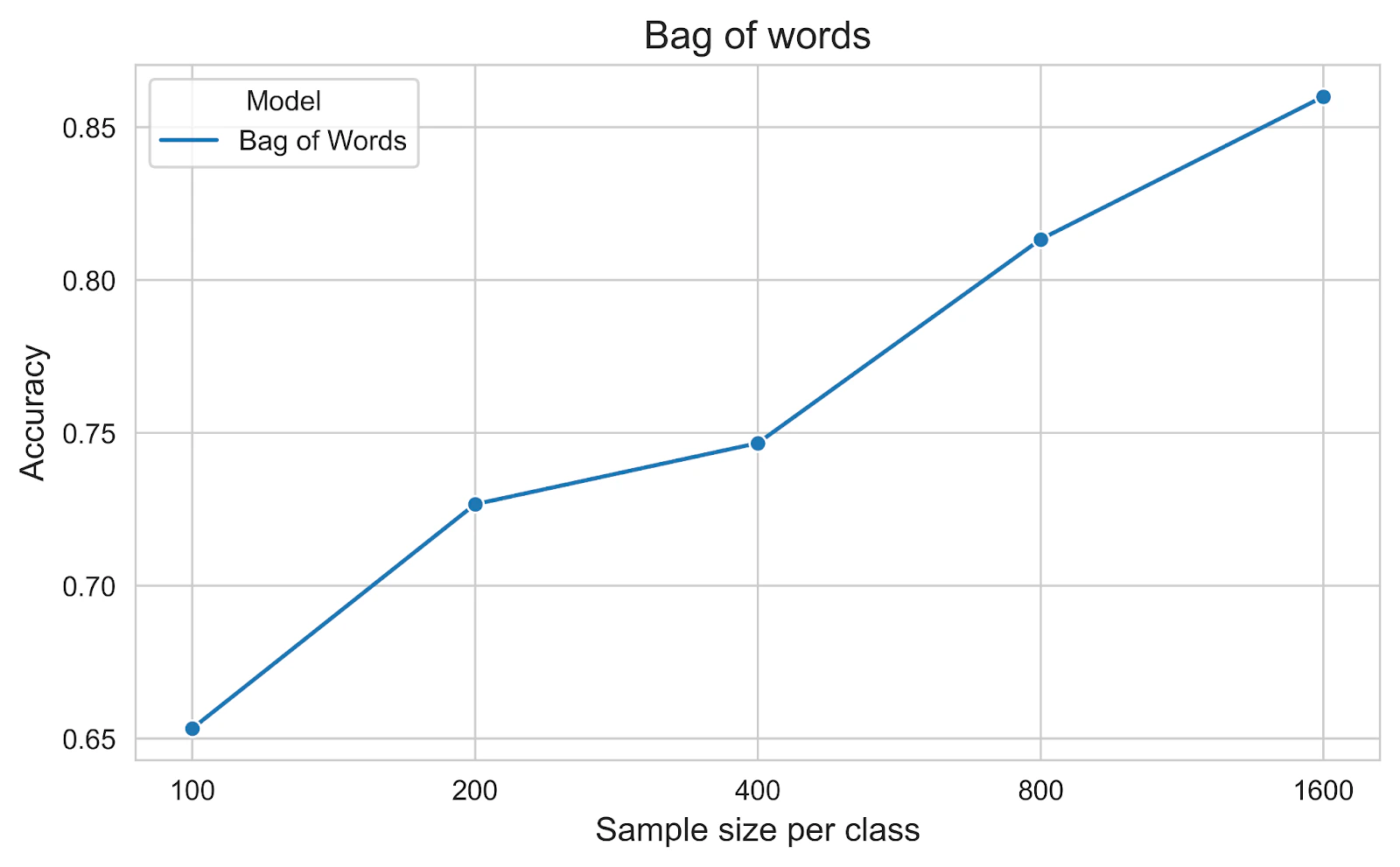
For the modelling part, we will use a simple Logistic Regression model, implemented in scikit-learn. The combination of BoW and Logistic Regression is a classic and powerful baseline for text classification tasks. Accuracy is used as the metric in this experiment. The below figure shows that the performance in the test set increases linearly with the exponential growth of the training size.
Dense vector representation
Some limitations of the BoW model include:
- The vector is sparse, which may not be suitable for all ML algorithms.
- The vector is high-dimensional, which may require a lot of memory and computation power.
- Order of words is ignored, which may lose some information.
To address these limitations, we can use a dense vector representation.
Word embeddings
Word embeddings are mathematical representations of words in a continuous vector space, where semantically similar words are mapped to nearby points. Each word is represented as a dense vector of floating point numbers, where the values are learned from analyzing large text corpora. To find the representation of a document, we can average the word embeddings of the words in the document. Two early notable models for word embeddings are Word2Vec and GloVe. Word2Vec fuses a shallow neural network to learn the embeddings, while GloVe is based on the co-occurrence matrix of words in the corpus. We will use GloVe in this experiment.
Since the introduction of the transformer architecture in the Attention is All You Need paper, transformer-based models have become the state-of-the-art for many NLP tasks. The self-attention mechanisms in the transformer architecture allow for capturing long-range dependencies and relationships between words, which was missed in earlier models. Its architecture is also suitable for parallelization, allowing for faster training and inference, compared to the sequential processing of RNN models. BERT is one of the most notable models in this family. Therefore, we also include BERT (base-uncased) in this experiment.
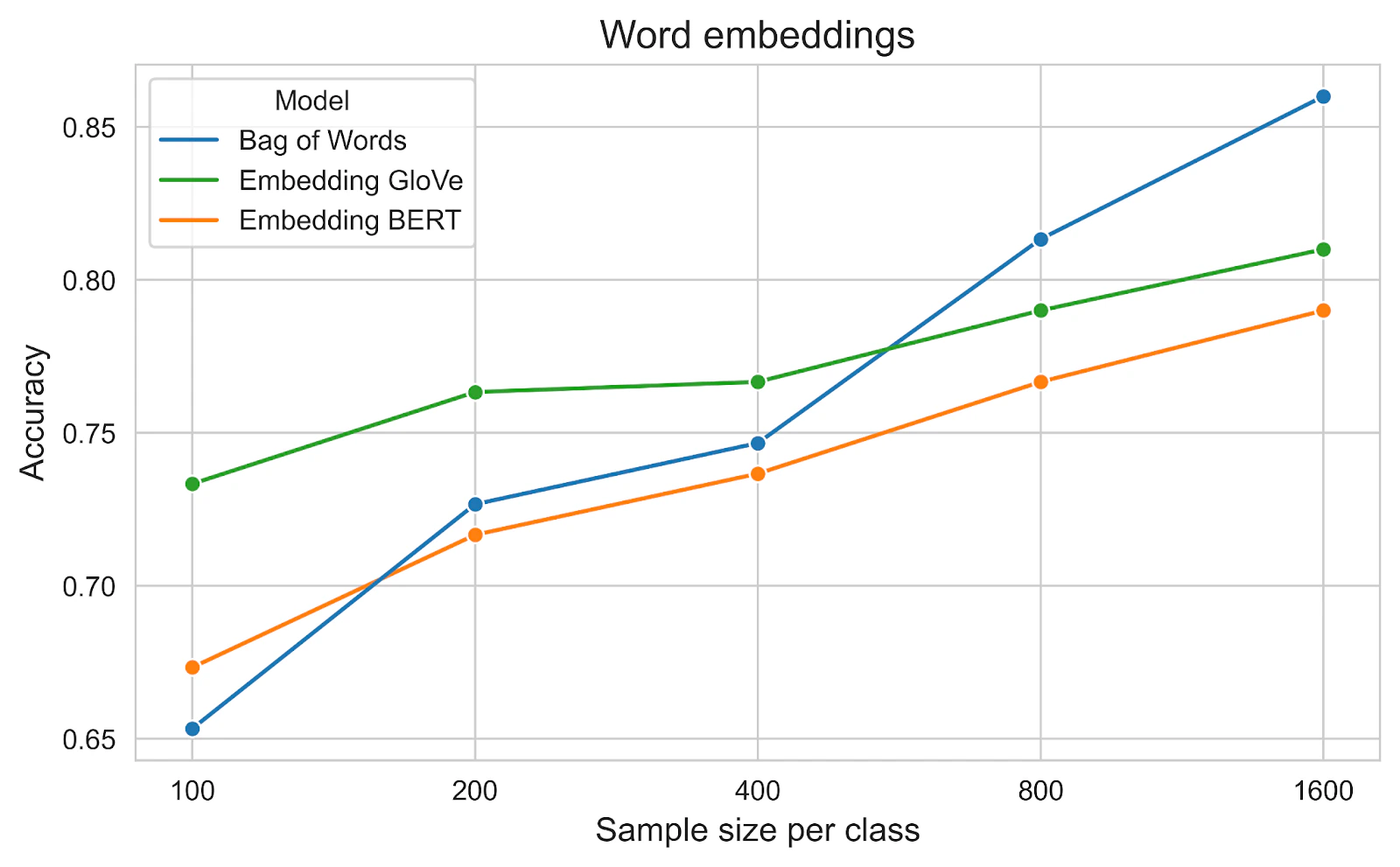
Similar to the previous section, after vectorization, we use a simple Logistic Regression model and accuracy as the metric. The figure below shows that the word embeddings are pre-trained and have a quick start when the training set size is small. However, the performance of GloVe and BERT is worse than BoW when the training set size is larger. One explanation could be that BoW is simpler but its representation is learned from the data with a similar distribution to the test set, whereas word embeddings are pre-trained with more generic data.
Document embeddings
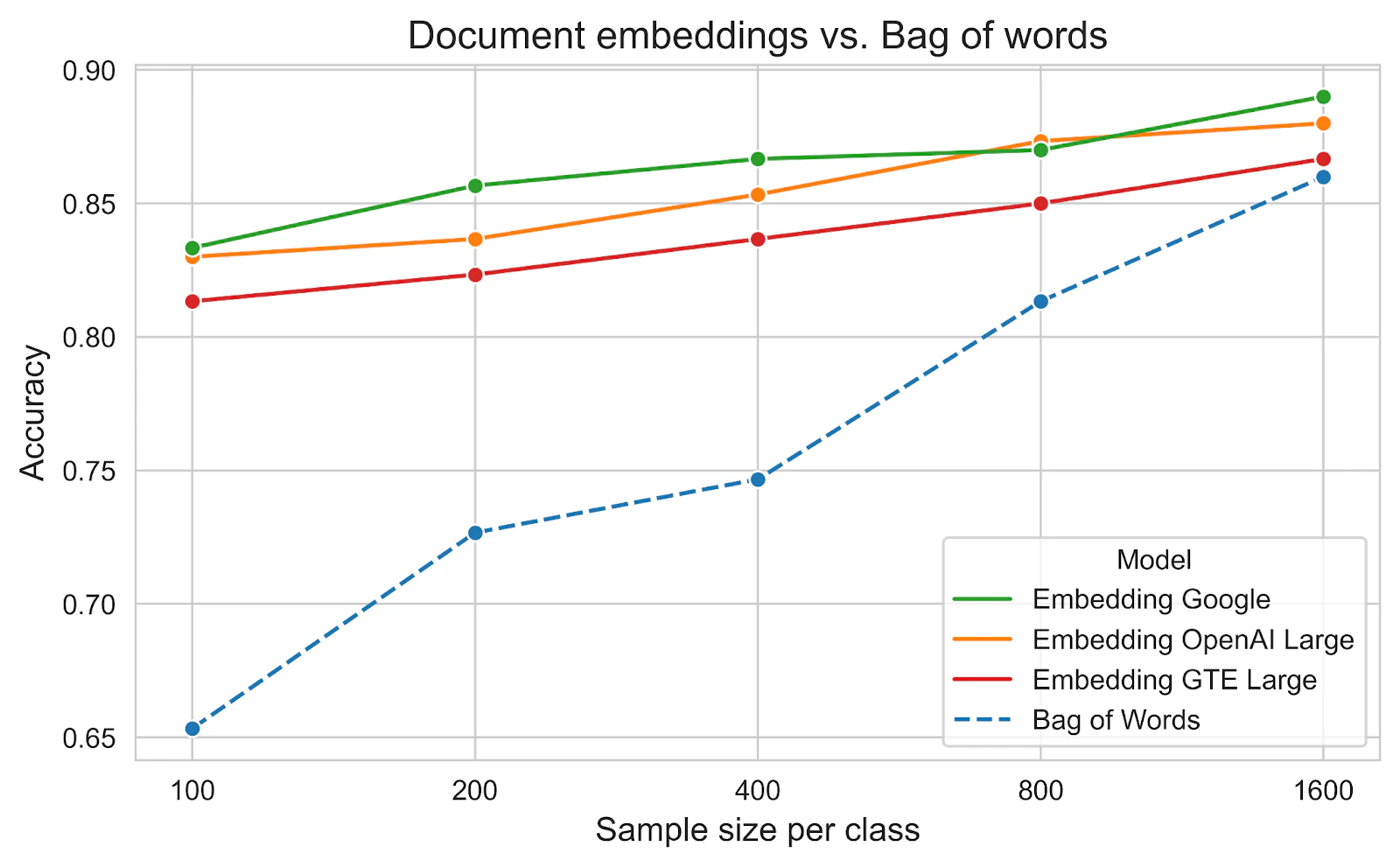
This section focuses on more modern techniques for representing documents as dense vectors directly rather than averaging their word embeddings. We will benchmark model gte-large-en-v1.5, which performs really well on the Massive Text Embedding Benchmark (MTEB) Leaderboard from Hugging Face given its small size (less than 1B parameters). We also include two other commercial models from OpenAI (text-embedding-3-large) and Google (text-embedding-004). These models outperform BoW at the greatest training set size and also show excellent performance at the smallest training set size.
Fine-tuning LLMs with classification head
In the embedding approach, the embeddings are pre-trained and fixed; only the weights of the logistic regression model are updated during training. This limits the performance of the model. Fine-tuning LLMs allows the model to learn the task-specific features and achieve better performance.
There are different approaches to choosing which part of the LLM to fine-tune, depending on the available training data. The final layer of the LLM, which is used to predict the next word, is replaced by a softmax layer for classification. Because we have a limited amount of training data, we will only fine-tune this layer.
We explore the performance of the following representative LLMs:
- BERT: the classic encoder-only transformer model (base-uncased 110M parameters)
- GPT-2: the classic decoder-only transformer model (small 124M parameters)
- Llama-3: the latest decoder-only LLM from Meta AI (8B and 70B parameters)
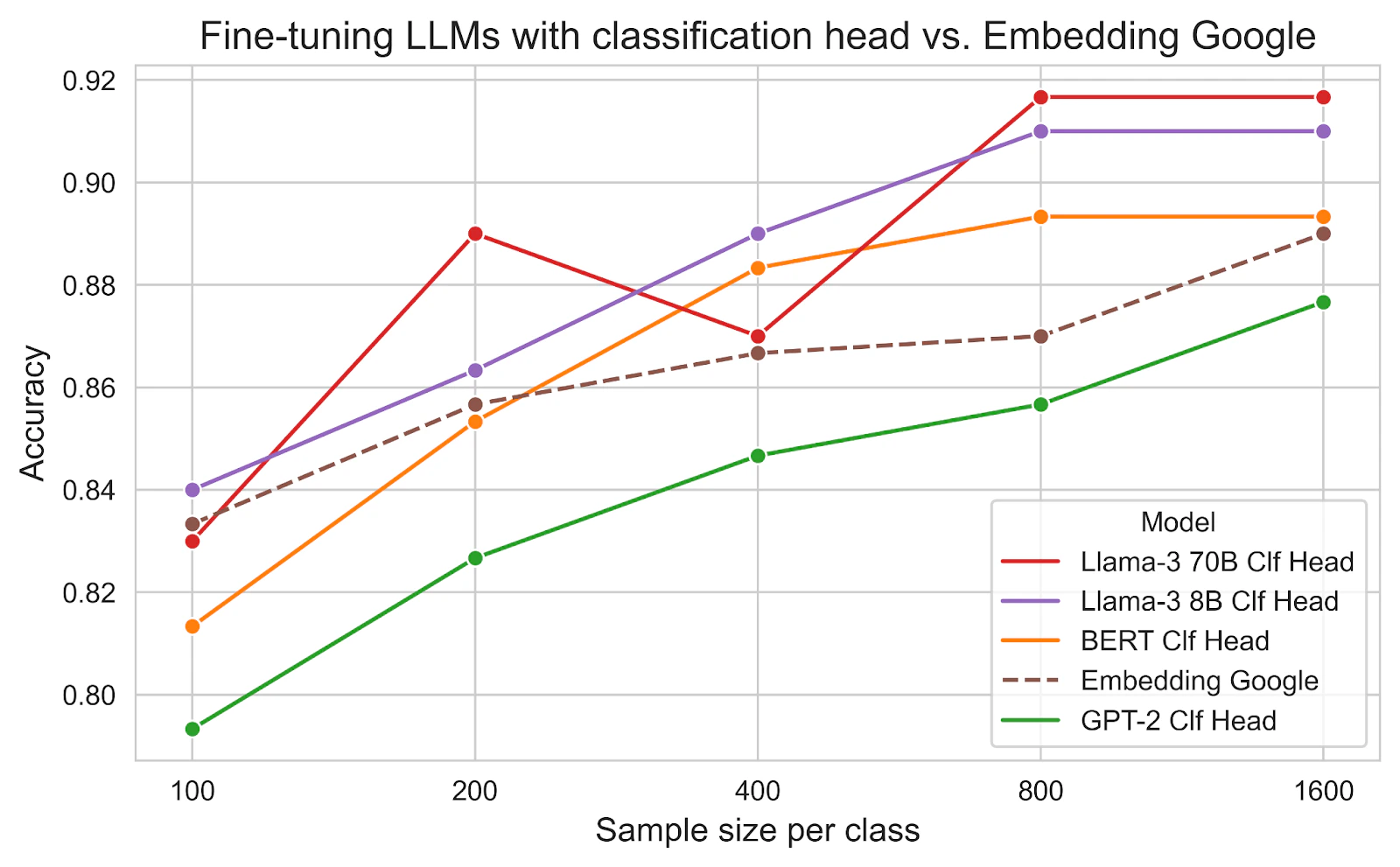
All models outperformed the previous best approach, Embedding Google, except for GPT-2. In general, the larger the model, the better the performance.
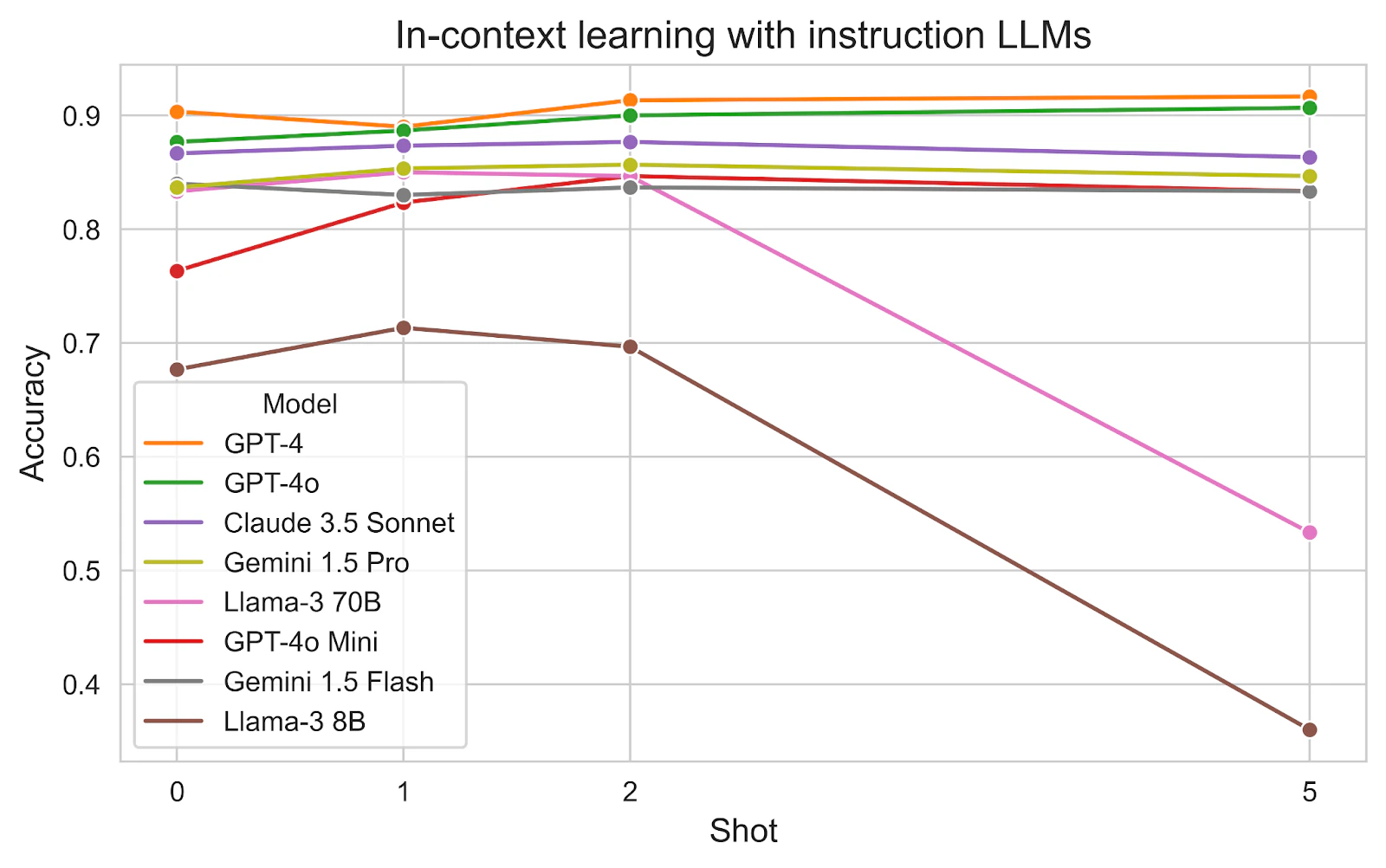
In-context learning with instruct LLMs
Since the introduction of the InstructGPT paper and the ChatGPT tool, LLMs can be used for classification tasks effectively via simple prompts. We explore models from notable LLM providers with a different number of examples provided in the prompt. In the prompt, we describe the task and the classes, and then provide examples for each class.
We discover some interesting findings:
- Model size: Large models GPT-4 and GPT-4o are clearly the best performers, followed by Claude 3.5 Sonnet and Gemini 1.5 Pro.
- Small models GPT-4o Mini, Gemini 1.5 and Llama-3 70B are equally good with 0-2 examples.
- The larger the model, the less examples are needed.
- Llama models suffer from a huge performance drop with 5 examples. It’s unclear why this is the case because the prompt length doesn’t reach the context limit yet.
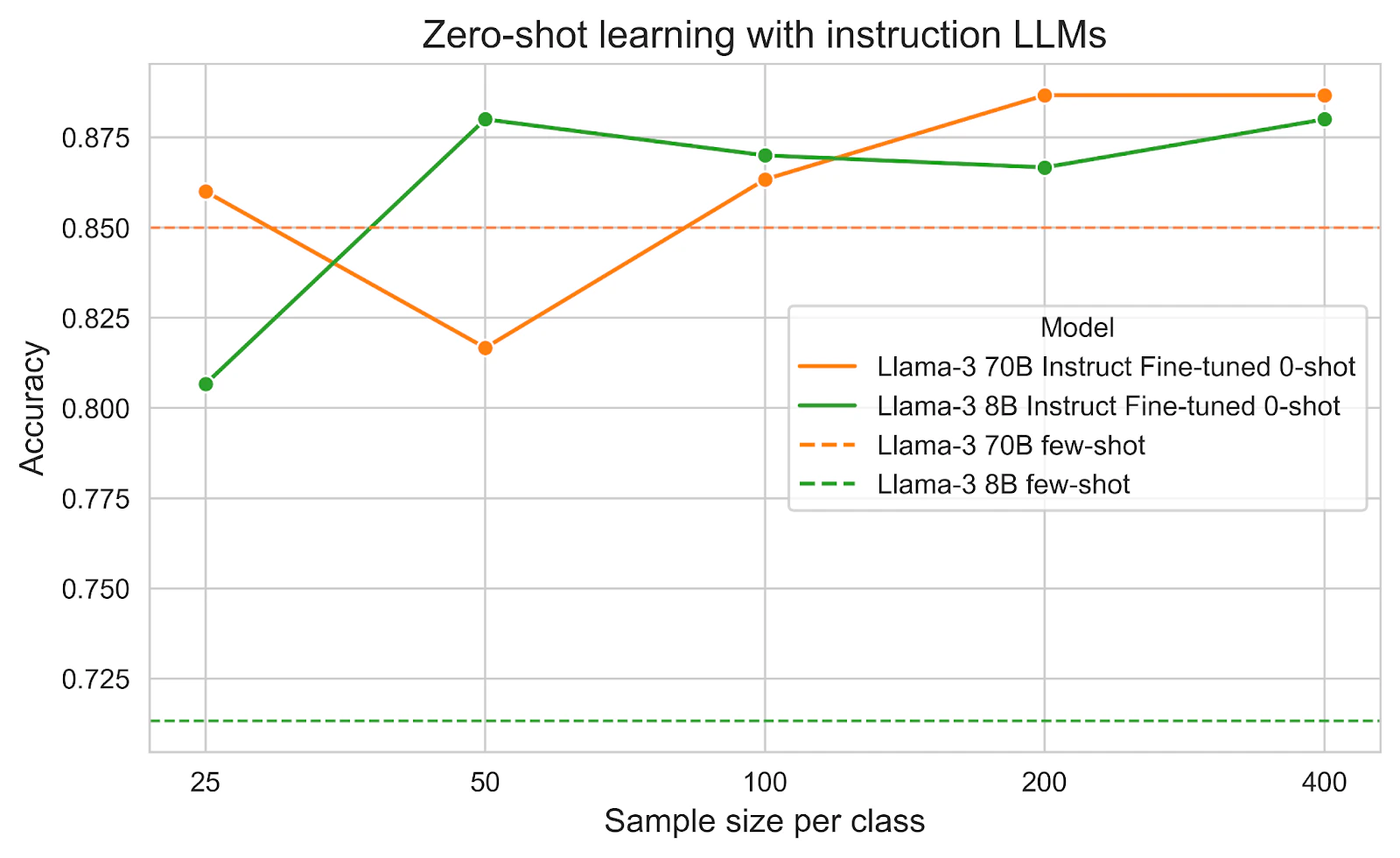
Zero-shot learning with instruction fine-tuned LLMs
Not in this specific task, but in harder tasks, in-context learning may require many examples to achieve good performance. This leads to a lengthy prompt with several drawbacks:
- Some LLMs have limited context windows and struggle with long prompts
- Increased inference latency due to processing more tokens
- Higher API costs from larger token counts
To address these issues, we can fine-tune the LLMs with instructions. Each item in the fine-tuning training data is a prompt-response pair. The fine-tuned model will understand the task deeply, adhere to the instruction, and make predictions with a much shorter prompt.
In the training data, we need to include a detailed description of the classes, same as in-context learning, to help the model understand the task. However, in the inference stage, we can just include the class names without any description and zero examples to reduce the prompt length significantly.
The below figure shows a great improvement between instruction fine-tuning and the default model with few-shot prompting. The smaller model Llama-3 8B benefited more from instruction fine-tuning.
Discussion
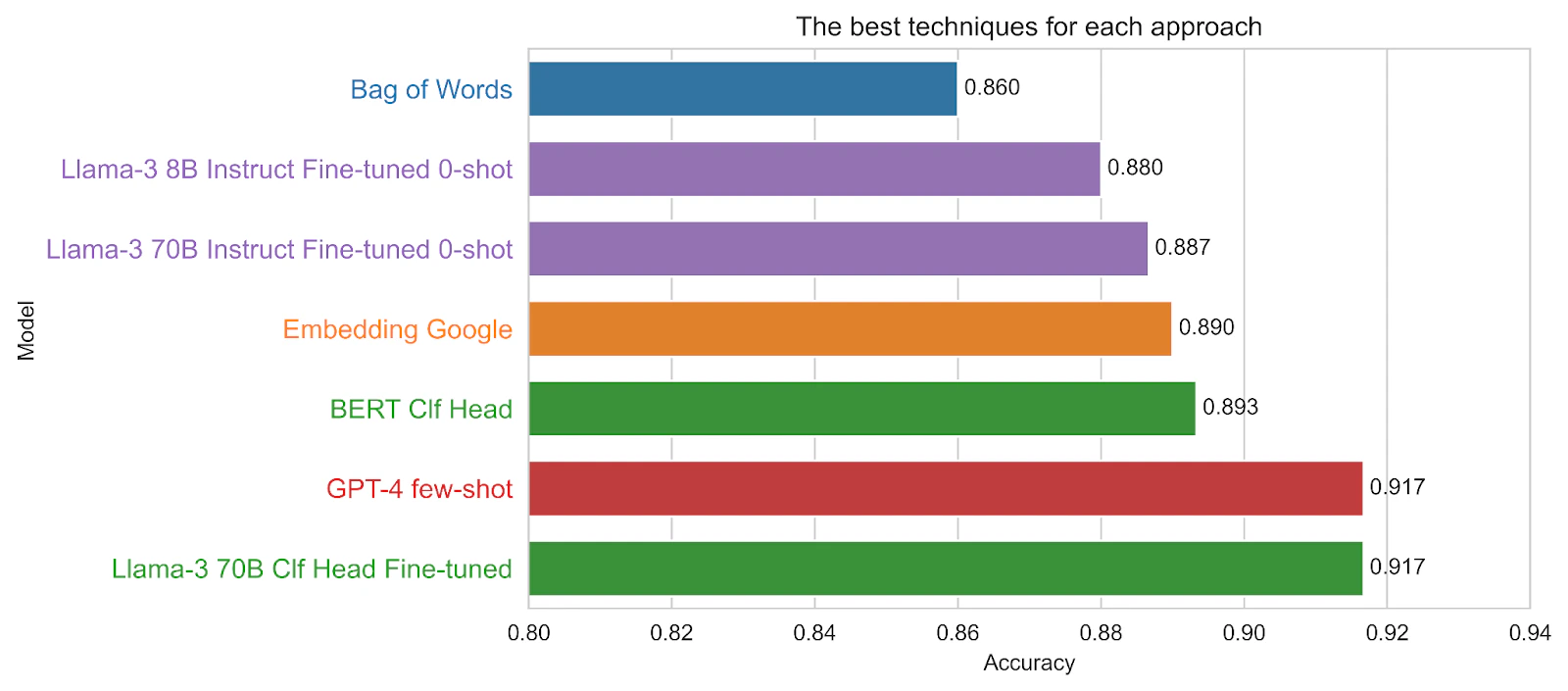
To summarize our analysis, the figure below compares the top-performing techniques across different approaches, highlighting several key insights:
- No Training Data: Few-shot prompting with GPT-4 delivers the highest accuracy, even surpassing all other methods with varying training data sizes. However, it comes with the trade-offs of being the slowest and most expensive option.
- Small Training Data (50x-100x): Instruction fine-tuning with Llama-3 70B achieves the best accuracy, with the smaller 8B model also performing well. For more challenging or domain-specific tasks, instruction fine-tuning with open-source models is likely to outperform generic commercial options. This method is also faster and more cost-effective.
- Medium Training Data (400x-800x): Fine-tuning the classification head with LLMs demonstrates clear advantages in this range. Fine-tuning a Llama-3 70B model achieves the highest accuracy, comparable to GPT-4. Smaller models like BERT-base (110M vs. 7B) offer slightly lower accuracy but much faster performance, making them a practical trade-off.
- Large training data (1600x): For this straightforward classification task, a classic Bag-of-Words (BoW) model performs surprisingly well compared to more advanced techniques. The linear trend in the first figure suggests that performance could improve further with additional training data. However, this approach has some limitations: it requires large amounts of training data and is monolingual, meaning different datasets are needed for different languages. In contrast, many large language models (LLMs) are inherently multilingual. Despite these limitations, BoW remains an extremely fast method.
Conclusion
In conclusion, text classification has come a long way with the rise of LLMs, offering transformative capabilities for real-world applications. In Brand Trust, these innovations in text classification enable us to classify webpage content and industry categories with precision, bolstering our ability to identify and mitigate domain impersonation risks. Beyond text classification, generative AI has powered advancements across our products, underscoring our commitment to applying AI to tackle complex challenges in cybersecurity.
Example size:
Phong's work explores a number of projects focused on NLP, anomaly detection, active learning and visualisation. He is a most known for his work behind Red Sift Radar.